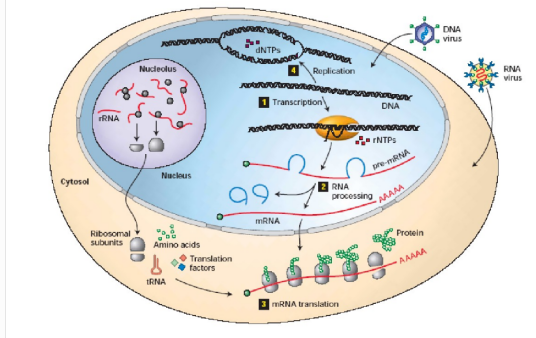
-
翻译 编辑
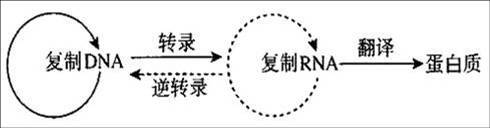 中心法则
中心法则翻译过程需要的原料:mRNA、tRNA、21种氨基酸、能量、酶、核糖体。
翻译的过程大致可分作三个阶段:起始、延长、终止。翻译主要在细胞质内的核糖体中进行,氨基酸分子在氨基酰-tRNA合成酶的催化作用下与特定的转运RNA结合并被带到核糖体上。生成的多肽链(即氨基酸链)需要通过正确折叠形成蛋白质,许多蛋白质在翻译结束后还需要在内质网上进行翻译后修饰才能具有真正的生物学活性。
游离的碱基以mRNA为直接模板,tRNA为氨基酸运载体,核蛋白体为装配场所,共同协调完成蛋白质生物合成的过程。在翻译过程中mRNA上的每个三联体密码子对应tRNA上的一个三联体反密码子,且这个反密码子只对应一个氨基酸,但是一个氨基酸可有多组密码子(密码子具有简并性)来表示。
一个激活的tRNA进入核糖体的A位(A位用于接受氨基酸,可记忆为Accept)与mRNA相配,肽酰转移酶在邻近的氨基酸间建立一个肽键,此后在P位(peptidyl-tRNA site,即肽酰基位点,也叫做“供点”)上的氨基酸离开它的tRNA与A位上的tRNA结合,核糖体则相对于mRNA向前滑动,原来在A位上的tRNA移动到P位上,原来在P位上的空的tRNA移动到E位(释放位点,记忆为Emission)上,然后在下一个tRNA进入A位之前被释放。
") 翻译(肽链的形成)
翻译(肽链的形成)
mRNA是翻译的模板。在原核生物和真核生物细胞内,mRNA的化学基础有所差异。
原核生物mRNA
在原核细胞内,参与翻译的mRNA具有以下特点:
(1)具有多个开放阅读框(ORF),即多顺反子,意味着同一条mRNA可以编码多个蛋白。特别注意可读框之间不重叠(除移码翻译涉及终止密码子和起始密码子的2个碱基重叠)。
(2)具有较为保守的核糖体结合位点(RBS)GGAGG,位置大概在起始密码子上游的3~9个碱基。
(3)自身可通过RBS招募小亚基核糖体RNA(16S·rRNA)。
(4)存在移码编译。在一些情况下,第一个ORF的终止密码子UGA和第二个ORF的AUG重叠,形成一个序列AUGA。当核糖体遇到UGA终止翻译后可以随即重启,向后移动-1位至起始密码子AUG,开始第二个ORF的翻译。如此的生物学意义是当且仅当第一个ORF成功翻译后,才会开启第二个ORF的翻译。
真核生物mRNA
相比原核细胞mRNA,真核细胞内参与翻译的mRNA具有以下不同:
(1)总是单ORF的(即每条链只能编码一个蛋白),即单顺反子。
(2)没有核糖体结合位点(仅有部分含有较为保守的Kozak序列:G/A——AUGG,其功能尚不完全明确)。
(3)核糖体的招募需要5'端的特殊结构(5'端加帽),加帽的反应过程可以简要表示如下:
PPP-→PP-+Pi
PP-+GMP→G-PPP-
总式:PPP-+GMP→G-PPP-+Pi
(4)起始因子结合5'端帽子结构(详见翻译的起始)以招募核糖体。
(5)核糖体从5'端开始扫描,直到遇到AUG开始翻译(以往认为大多是遇到第一个AUG即开始翻译,后续观点认为这种情况并不常见,具体机制尚不完全明确)。
 图1 tRNA结构
图1 tRNA结构
由于翻译的氨基酸需要,tRNA在单个细胞内可有很多种,下面将讨论各种mRNA之间的保守部分和可变部分。
保守部分
在不同的tRNA中,以下部分是所有tRNA共有不变的:
(1)3'端CCA序列(由相应酶不依赖特异性模板而添加的)。
(2)保守碱基,包括:位于T-loop的7个、位于D-loop的4个、位于Anticodon-loop的1个。
(3)位于各臂间的多个碱基对。
可变部分
在不同的tRNA中,以下部分是特异性的:
(1)反密码子。
(2)Variable-loop(可变环)的大小:1类在3~5个碱基对左右,2类在13~21个碱基对左右。
(3)识别子(位于3'端的四个碱基),其主要用于区分不同种类的tRNA。
碱基配对原则
翻译过程严格按照碱基互补配对原则进行。值得注意的是,转录组成RNA的碱基中,没有T(胸腺嘧啶),而是U(尿嘧啶),所以配对原则如下所示。
DNA → RNA
A ,腺嘌呤→ U,尿嘧啶
T ,胸腺嘧啶→ A ,腺嘌呤
C,胞嘧啶→ G,鸟嘌呤.
由于密码子的摆动性,反密码子第1位碱基与密码子第3三位碱基之间配对称多样性,可能配对方式如下:
I →A,U,C
U →A,G
G →C,U
其中,I代表次黄嘌呤核苷(iNOsine),在tRNA反密码子中出现。而其他两位的配对方式即是严格的沃森-克里克配对方式。
特别强调的是,虽然氨基酸种类很多,但是由于tRNA密码子的摆动性,可以缩减所需要的tRNA数量。比如异亮氨酸的密码子是AUA、AUC或AUU,则对应的反密码子只需要是UAI一种即可。
翻译的化学本质是单个氨基酸脱水缩合形成肽链,这一过程需要多种酶的参与。而在体内,多种酶参与的多种化学反应组成了翻译的生物化学途径。就化学层面来看,翻译主要涉及到三个化学步骤:氨基酸的腺苷化(Amino Acid Adenylation)、tRNA装载(tRNA charging)、肽键的形成。
腺苷化反应和tRNA装载
 氨基酸分子结构通式
氨基酸分子结构通式
这个化学过程可简要概括如下:
AA + ATP → PPi + AA-AMP
PPi → 2Pi
总式:AA + ATP → 2PPi + AA-AMP
特别值得注意的是,在这个反应中,三磷酸腺苷内的高能磷酸键得以保留。
tRNA装载过程是AA-AMP和tRNA发生反应最终形成AA-tRNA的过程。其化学本质是tRNA受体臂上的3'端羟基-OH攻击AA-AMP上连接P原子和C原子的O原子,最终形成装载完毕的tRNA。通过这种方式装载完毕的tRNA依然保留了一个高能键。高能键的保留对于后续反应的发生相当重要。
这两部反应是由氨酰-tRNA合成酶(AA-tRNA synthetase)催化完成的。后续将对该酶的结构生物学基础做进一步探讨。
肽键的形成
这一步反应是整个分子生物学过程的核心,但其化学本质很简单,重点是其生物体内催化的过程。在以往的观点里,核糖体rRNA的具体序列或许对于肽键形成至关重要,因为在核糖体的反应核心并没有蛋白质的参与,提示着rRNA对于肽键的合成起到主要的催化作用。而经过后续研究,当前普遍认为rRNA对于核心反应的催化并非具体序列依赖的化学催化,而更像是整体序列共同作用导致的物理结构催化。即rRNA通过整体序列(和蛋白互作)形成特定的结构,确保核糖体A位点和P位点的;两个tRNA受体臂上的氨基酸能够近距离正确接触,催化反应的发生。
而tRNA自身的结构,甚至是氨基酸本身其他结构都在这个反应里起到了一定程度的重要催化作用,来确保这个反应的发生。
参与翻译生化反应的有多种酶,但其核心生化反应主要由两类酶参与:催化腺苷化反应和tRNA装载的氨酰-tRNA合成酶、催化肽键合成的核糖体核酶。下面将进一步探讨这两种酶的结构生物学基础,以及它们确保反应准确发生的校正机制。
氨酰-tRNA合成酶
氨酰-tRNA合成酶有四个结构域和三个活性位点。由于每种tRNA只能结合特定氨基酸,所以氨酰-tRNA合成酶必须确保tRNA和氨基酸之间的正确配对。
其四个结构域分别结合tRNA受体臂(第1结构域)、反密码子区域(第2结构域,其中1个碱基用来被识别)、ATP和正确AA(第3结构域)、错误AA(第4结构域)。
三个活性位点分别位于第1结构域(催化tRNA装载)、第3结构域(催化腺苷化反应)、第4结构域(催化错误氨基酸水解)。
错误氨基酸在这里一般指的是和该tRNA不匹配,但又由于化学性质类似而容易被错误装配的氨基酸。氨酰-tRNA第3结构域内的AA结合位点对于匹配的正确AA具有高亲和力,而对错误AA亲和力较低,但依然会有概率结合而催化后续的两步反应。但由于第4结构域对错误AA的高亲和力,可以大概率将周围的错误AA先行“捕捉”并且水解,防止其参与后续反应。这就是氨酰-tRNA合成酶的第一个校正机制,是化学或酶学机制。
第二个校正机制是动力学机制。正确的AA和tRNA组由于在合成酶中处于正确的位置而更容易得以被催化,导致反应的发生。
值得注意的是,翻译和转录的校正机制往往没有基因复制的高保真度。从生物学意义角度来看,翻译的单个氨基酸出错只会影响一个蛋白的功能,而基因复制错误则可能会影响一类蛋白终生的表达。
核糖体核酶
核糖体由大小两个亚基组成,其rRNA占到组分的50%,剩余的50%是一些小型蛋白。蛋白质的主要作用是维持rRNA的正确折叠,但值得注意的是,所有的催化作用都是rRNA介导的。
核糖体有两个通道:mRNA-tRNA通道(贯穿三个tRNA结合位点:A、P、E)和肽链出口通道。大部分新合成的肽链都是在离开核糖体后才开始折叠,而在肽链出口通道可以先行形成α螺旋。
核糖体的三个位点各自结合不同的组分。A位点结合AA-tRNA,P位点结合肽链-tRNA和起始AA-tRNA。E位点结合即将释放的tRNA。最重要的肽键合成发生于A位点和P位点之间,故位于这两个位点的tRNA的受体臂3'端在空间结构上距离很近以方便反应的发生,而E位点则距离较远。在A、P位点的tRNA均和mRNA存在氢键互作,而在E位点的tRNA距离mRNA较远,并无互作,方便其尽快脱离。
在核糖体中,有两个重要的区域:肽酰转移中心(肽键合成)和解码中心(mRNA-tRNA互作)。在tRNA和rRNA的共同作用下,肽酰转移得以催化。而tRNA的正确匹配在肽键合成过程中是必须的(详见下文翻译的延伸)。
原核细胞
原核细胞的翻译起始过程大概可以分为以下几个过程:
(1)翻译起始因子IF3结合到小亚基的E位点,同时也横跨至P位点;(这一过程在起始之初就已经完成)起始因子IF1结合至A位点;
(2)起始因子IF2·GTP被IF3和IF1招募至P位点;
(3)起始fMet·tRNA一方面被mRNA起始密码子AUG招募,另一方面被已经结合到P位点的IF2·GTP招募,进一步结合到P位点,这一过程伴随着核糖体小亚基通过mRNA上的核糖体结合位点序列(RBS)识别结合到mRNA上;
(4)当tRNA和mRNA配对后,起始因子IF3稳定性降低;
(5)IF2·GTP进一步招募大亚基;
(6)大亚基的结合催化IF2上GTP的水解,形成对P位点亲和力较低的IF2·GDP,后者随后从核糖体上脱离;
(7)由于IF2的脱离,大小亚基结合进一步紧密,置换出IF3和IF1,形成了起始状态的核糖体复合物。
注:实验分析表明,当IF3和IF1不存在时,起始tRNA倾向于在IF2之前结合至P位点,提示起始tRNA可以直接被起始密码子招募;当IF3和IF1存在时,起始tRNA倾向于在IF2之后结合P位点,提示IF2可以被IF3和IF1有力招募,而tRNA也可以进一步被IF2招募。
真核细胞
真核细胞会涉及到更多的起始因子包括:eIF1,1A,3,5,4(EGAB),2,5B,1A。其中它们和原核细胞起始因子按照功能可以大体划分配对如下:
真核细胞 | 原核细胞 |
eIF1,eIF3,eIF5 | IF3 |
eIF2 | IF2 |
eIF5B | |
eIF4E,eIF4G,eIF4A,eIF4B | — |
eIF1A | IF1 |
以核糖体为核心,真核细胞翻译起始过程也可概括成如下步骤:
A. 核糖体的前期准备
(1)eIF1,3,5围绕E位点结合至小亚基,eIF1A围绕A位点结合至小亚基;
(2)eIF2·GTP在胞质中结合Met-tRNA形成三原复合物;
(3)三原复合物进一步结合到小亚基复合物(小亚基以及eIF1,1A,3,5)中小亚基P位点上形成43S复合物;
B. mRNA的准备
(1)eIF4E识别mRNA的5‘端帽子;
(2)eIF4G作为支架蛋白结合至eIF4E并连接eIF4A,eIF4A结合至mRNA上;
(3)eIF4B和eIF4A互作,激活eIF4A的活性;
(4)eIF4A利用其解旋酶活性解旋mRNA,去除其二级、三级结构;
C. mRNA的装载
(1)43S复合物通过eIF3和eIF4E互作,eIF1A和eIF4A互作将mRNA进行招募形成48S复合物;
(2)eIF4A利用其解旋酶活性,充当转位酶作用,移动mRNA进行扫描;
(3)遇到第一个起始密码子AUG后,密码子和tRNA配对,阻碍了eIF4A的转位,扫描停止;
(4)二者的配对,刺激eIF2的GTP水解,eIF2·GDP和小亚基亲和力较低,从小亚基复合物上脱离下来,伴随着其他除eIF4A以外的起始因子全部脱离;
(5)eIF5B·GTP被起始tRNA和eIF1A招募;
D. 大亚基的装载
(1)eIF5·GTP招募大亚基;
(2)大亚基的结合刺激eIF5上的GTP水解,eIF5·GDP亲和力较低,从核糖体上脱离下来;
(3)大亚基获得更高亲和力,进一步将eIF1A置换出来,进入起始状态。
注:并非所有真核细胞内的翻译均需要eIF4E对5’端帽子的识别,有下列三种特殊情况利用内部核糖体插入位点(IREs)进行RNA的装配:
Group 1 | 利用特殊结构直接招募核糖体大小亚基,不需要任何起始因子和起始tRNA。 例:一些病毒如CrPV入侵真核细胞后,通过抑制起始因子进一步抑制真核细胞内部的蛋白表达,但其自身特殊的mRNA结构可以直接招募大小亚基来绕过起始因子和起始tRNA阶段,直接进入翻译的中间延伸状态,获得核糖体翻译的绝对选择性。 |
Group 2 | IREs招募小亚基,但依然需要部分eIF和起始tRNA。 例:部分IREs直接结合eIF4G进一步招募eIF4A。 |
Group 3 | 需要IREs特殊的结合蛋白,同时也需要大部分eIF和起始tRNA。 例:细胞凋亡。细胞在凋亡时,希望减少其他蛋白的表达(通过抑制eIF4E),而大量表达凋亡相关蛋白。如死亡相关蛋白5(DAP5)利用其IREs序列招募相关因子(ITAF),后者充当eIF4G的eIF4A结合区域的作用,绕过eIF4E,直接结合eIF4A进行后续装载。通过这样的机制可以巧妙的降低其他蛋白(需要eIF4E)的表达,但是提高凋亡相关蛋白的表达。 |
此过程在真核细胞和原核细胞中高度类似,下面只以原核细胞为例进行讨论。涉及到的因子主要有EF·Tu和EF·G,在真核细胞中对应的名称分别是是eEF1和eEF2。
A. tRNA的转运和入位
(1)非起始AA·tRNA结合EF·Tu·GTP形成一个三元复合物;
(2)该三元复合物结合至核糖体P位点,tRNA反密码子和mRNA密码子进行配对,伴随着tRNA构象改变;
(3)小亚基RNA中G530、A1492、A1493等位点和密码子及反密码子互作,使其稳定配对;
(4)EF·Tu在核糖体大亚基因子结合位点(FBS)His-84氨基酸残基的刺激下将GTP水解成GDP和Pi;
(5)EF·Tu·GDP对核糖体亲和力较低从中释放;
(6)tRNA进一步发生构象变化,使得其受体臂3‘端和P位点上受体臂3’端距离很近,为肽链的转移作准备;
tRNA的特异性配对大多在此过程中得以筛选确认。如果反密码子和密码子不能成功匹配,会影响以下几个因素导致入位不能完成:
①由于tRNA底部密码子配对有误,结构异常,EF·Tu顶部的GTP水解位点不能和HBS完全接触,导致GTP水解不能发生;
②错误的结构,导致tRNA不能发生正确的构象变化,EF·Tu无法释放;
③由于错误的配对,入位时产生的压力底部无法承受,导致入位失败。
B. 肽链的转移
肽链的转移化学本质即氨基和羧基的脱水缩合。很长一段时间人们普遍认为核糖体的rRNA保守序列对于脱水缩合起到关键的化学催化作用,后事实证明,rRNA仅仅起到结构上的物理催化(上千个序列共同作用而形成的结构),和其任何特定保守序列都没有完全的直接关系。而tRNA的结构被认为起到了很重要的化学催化作用。
C. 核糖体的移位
(1)肽链转移后,两个tRNA进行在不稳定的常态和扭转态(hybrid)之间进行摆动;
(2)EF·G·GTP在tRNA处于扭转态时结合到A位点上部,锁定扭转态结构;
(3)在HBS中His-84残基的刺激下,GTP发生水解,产生EF·G·GDP·Pi,伴随着EF·G的构象改变,结构深入A位点,一方面解锁扭转态结构,一方面将两个tRNA推向E位点和P位点;
(4)Pi从EF·G上释放,使得后者构象再次发生变化,回归最初的结合位置;
(5)EF·G·GDP对核糖体亲和力较弱,从核糖体上释放;
(6)进入E位点的tRNA不再维持和mRNA的配对,很快得以释放。
注:扭转态即tRNA底部依然在该位点,但顶部已经进入下一位点的扭曲状态。
本过程细胞主要需完成以下目标:
(1)使翻译停止,不再有新的氨基酸掺入;
(2)释放合成的多肽链;
(3)释放结合在mRNA上的各组分;
(4)确保核糖体大小亚基以及重要因子的重复利用。
原核细胞和真核细胞在此过程的处理上有明显不同,下面将分开介绍。
1.原核细胞
A.肽链的释放
(1)释放因子RF1/2 (tRNA结构类似)结合A位点,识别并匹配终止密码子;
(2)RF1/2的GGQ 基序(tRNA受体臂结构类似)催化肽链的脱离(以HOH替代HO-进行反应);
(3)RF1/2进一步招募RF3·GDP结合到核糖体大亚基上;
(4)RF3将GDP换成GTP(鸟苷酸交换因子活性),这一过程伴随的构象改变释放RF1/2,使其脱离核糖体;
(5)RF3利用自身的GTP水解活性水解GTP回归GDP结合状态,随后从大亚基上脱离。
B. 两个tRNA的释放
(1)因子RRF(扭转态tRNA结构类似)结合到空出来的A位点;
(2)此时具有扭转态tRNA类似构象的复合物引诱EF·G·GTP结合到大亚基位置并锁定扭转态结构;
(3)EF·G·GTP水解GTP转化为EF·G·GDP·Pi状态,这一步伴随构象改变解锁原本的扭转态结构,将原本E位点的tRNA推出核糖体,将P位点的tRNA推到E位点,将RRF从A位点推到P位点;
(4)Pi从EF·G释放,导致构象进一步变化,EF·G脱离,而E位点的tRNA由于较低亲和性也从核糖体脱离,RRF由于对P位点的亲和性低,也脱离。
C. 大小亚基的分离
(1)由于此时的大小亚基三个位点全空了,翻译起始因子IF3得以进入结合到E位点,降低大小亚基之间的亲和性,使其分离;
(2)IF3继续结合在小亚基上,准备下一轮起始。
2.真核细胞
A. 肽链的释放
(1)eRF3充当类似于eEF1(或EF-Tu)的作用,以GTP结合状态结合到eRF1/2上;
(2)通过eRF3的介导,eRF1/2被运输到A位点;
(3)eRF1/2识别终止密码子(类似于tRNA的密码子配对),正确的构象传递使得核糖体FBS和eRF3的GTP结合位点互作;
(4)FBS刺激GTP水解,eRF3转为GDP结合态;
(5)eRF3·GDP很快从核糖体上脱离,伴随着eRF1/2的类似于tRNA的入位过程;
(6)eRF1/2的GGQ基序催化肽链的脱离;
B. 剩余组分的脱离
Rli·ATP具有转位酶活性,通过水解ATP沿着mRNA转位,以一种类似于转录终止的方式,将其他组分从mRNA上推离下来。
关于真核细胞翻译过程的模型认为eIF4G可以结合mRNA的5‘端poly-A尾,进而将mRNA形成闭环,结合多个核糖体,以提高效率。且在此模型下,核糖体在翻译完毕解离后,可直接在起点重新起始,更符合核糖体的循环利用规律。
任何体内的生物反应都必须在调控的作用下,才有意义。翻译的调控是十分精密复杂的。在原核生物里翻译调控的基本单位不是单个的mRNA而是mRNA中的单个阅读框。以ATP合成酶为例,在原核生物里,该酶包含A、B、C、D、E、F、G、H等多个亚基,其基因拷贝均为一份,在转录时转录到同一个mRNA上。而实际每个酶中各个亚基的比例并非均等,如E亚基的需求量是C亚基的10倍。这就必须要求在翻译层面进行调控。
相比于转录调控,翻译调控更迅速、更高效,且可以通过对翻译的调控进一步控制不同蛋白的空间特异性。同时翻译调控也可以回复错误转录造成的危害。
无论针对翻译、转录还是复制,研究调控首先要研究一个生理过程的限速步骤。限速步骤的调控才具有重要的生物学意义。在这里要引入一个新的单位:核糖体密度(RD)。其计算公式如下 :

其中



一、原核细胞
在整体上,原核细胞可通过改变核糖体结合位点(RBS)序列或者在RBS邻域制造二级结构来阻止小亚基和mRNA的结合进而阻止翻译的起始。一方面由于RBS序列固定,改变其序列将会造成所有mRNA停止翻译。另一方面由于改变序列并非快速准确的调控方法,针对单个转录本,原核细胞倾向于采取以下几种方式进行调控:
(1)蛋白依赖的——通过蛋白质特异性结合到RBS和起始密码子AUG之间的序列以通过物理方式阻止小亚基和mRNA结合,但该特异性序列不能包括RBS(否则将可能会导致所有转录本停止翻译)。
(2)mRNA依赖的——通过ORF和下游序列的杂交来阻止该ORF的起始。但如果该ORF上游有其他开放起始位点,则该ORF可以被上游翻译启动(核糖体翻译到下游时,将其解旋),这样的好处是当且仅当第一个ORF翻译时,第二个ORF才可以翻译。
(3)其他——在特殊情况下,原核细胞也可以通过特殊的负反馈途径和一些特殊的小RNA(sRNA)进行调控。
以核糖体蛋白的翻译调控为例,我们来讨论一个典型的mRNA、蛋白依赖混合的负反馈调控模式。当周围存在自由rRNA时,新生核糖体蛋白结合rRNA的相应位点来促使其折叠形成适当结构,此时核糖体蛋白正常翻译。而当周围存在多余的核糖体蛋白时,该蛋白会结合到核糖体蛋白转录本的ORF和RBS之间,以促进钙ORF和下游序列的杂交,抑制翻译起始。
而其他的调控方法内,最为典型的是核糖开关。核糖开关是一类小mRNA,其能翻译出一些蛋白质,后者催化产生一些类别的SAM(小活性分子)。当SAM存在时,可促使mRNA发生构象变化,在ORF和RBS等关键位点处形成二级结构,阻遏翻译起始。当SAM不存在时,阻遏不能形成,翻译得以继续。
一些小RNA(sRNA)也可以起到翻译调控的作用。原核生物的小RNA大小基本在80-110核苷酸。它可以通过自身和RBS互补的序列来解除RBS参与的自体杂交,进而回复翻译。它也可以直接和开放的RBS杂交阻遏翻译,具有典型的两重性。
二、真核细胞
值得注意的是,虽然在原核生物细胞内,翻译的起始过程依然有IF1、IF2、IF3三类因子的参与(真正耗能的步骤是IF2介导的起始tRNA入位和大亚基招募),但原核细胞几乎没有以这些蛋白因子为靶点进行的调控模式。在真核细胞内,由于大量翻译起始因子的参与,大量对于翻译的调控也是以这些蛋白因子为靶点进行的。
和原核细胞类似,真核细胞的翻译调控也可分为基因特异性调控和全局调控。其靶点主要有三个:起始tRNA的入位、mRNA-eIF4复合物的形成、mRNA的扫描。
最常见的全局调控之一是激酶(如GCN2)磷酸化eIF2,使原本使eIF2·GDP转为eIF2·GTP的eIF2B失去鸟苷酸交换因子活性,反应不能发生,eIF2·GTP减少,tRNA入位减少,细胞内全局翻译速率降低。
另一种常见的全局调控是利用4EBP(eIF4E结合蛋白)与eIF4G竞争,识别并结合eIF4E。而激酶可以磷酸化4EBP以使其不具有结合4E的活性。这一通路常被视作一些营养通路(如mTOR)的效应下游。
基因特异性调控主要依赖于mRNA的特有序列。常见的例子是Bruno蛋白可以特异性结合一些mRNA下游元件,而与此同时Cup蛋白与eIF4E结合。由于Bruno可以和Cup互作,进而形成mRNA闭合环路,阻止翻译的进一步发生。
另一个特异性调控的例子是铁蛋白的翻译调控。由于铁蛋白主要参与二价铁离子的代谢,在二价铁离子存在时需要被高度表达以应激,防止其进一步破坏细胞。铁蛋白mRNA是一类带有IRE序列的mRNA。当铁离子不存在时,IRP(IRE结合蛋白)可结合IRE序列,阻碍4A因子对mRNA的AUG的扫描。而当铁离子存在时,IRP被释放,扫描得以回复。
约50%的智人(Homo Sapiens)基因带有上游起始密码子(上游AUG)。尽管真核细胞每条mRNA只表达一个蛋白,但其依然可以带有多个上游可读框和上游AUG,只是其并不翻译产生具有生物学意义的蛋白。理论上,真核细胞会翻译其mRNA上游到下游扫描遇到的第一个AUG,并且在翻译完成后解离。这意味着上游AUG的存在将阻碍下游AUG的启动,进而阻碍具有生物学意义的蛋白的表达。但这并不是绝对的,上游AUG/ORF的确起到负调控的作用,但不能完全阻止下游ORF的翻译。其具体机制尚不完全清楚。
上游密码子的克服
一般认为核糖体可以通过以下两种方式来克服上游AUG的阻碍:
(1)直接略过第一个AUG。
一般有两种猜想支持这一个方法:Kozak序列和二级结构。由于一部分上游AUG带有较为保守的Kozak序列:A/GNNAUGG,或许生物可以通过某种机制识别这一序列进而直接略过上游AUG的翻译。同时,也有研究表明在上游AUG周围出现二级结构可以使得其被核糖体略过而不启动翻译,而其在机制上并不容易理解,因为理论上eIF4A会解旋所有二级结构,保证翻译不受影响。
(2)翻译在上游ORF终止后重新启动。
由于ORF大多很短(只有3-10个氨基酸),核糖体小亚基或许在翻译结束后继续和mRNA互作,并持续扫描而并不解离下来。一般认为此类机制下的翻译重启也会受到下游终止密码子的影响。
上游密码子的调控作用
已有证据表明,上游密码子是细胞内经常采取的一种通用调节翻译的机制。下面以GCN4在响应低氨基酸应激过程中的翻译调控为例进行讨论。
GCN4作为一类蛋白因子,可以上调一大类氨基酸合成酶的表达。GCN4的mRNA具有非常特殊的5'端结构,大体如下:
 GCN4的mRNA具有非常特殊的5'端结构
GCN4的mRNA具有非常特殊的5'端结构
突变4个uORF的起始密码子AUG,依次建立了4个突变组M1~4,同时再另取一组将其ORF2~4起始密码子AUG均突变,建立了第5个突变组M5,保留一组野生型(WT)作对照,实验观察GCN4在高氨基酸和低氨基酸下的表达情况,可以得到如下结果(+表示表达,-表示不表达):
组别 | 低氨基酸 | 高氨基酸 |
M1 | - | - |
M2 | + | - |
M3 | + | - |
M4 | + | +/- |
M5 | + | + |
WT | + | - |
其调控机制是这样的:
GCN2是GCN4的同家族蛋白,可以响应低氨基酸状态,进一步作为激酶磷酸化eIF2。磷酸化的eIF2可以抑制eIF2B的鸟苷酸交换因子活性。不同寻常的是,核糖体在翻译经过ORF1起始密码子后,部分翻译起始因子得以保留,待经过终止密码子后,大亚基解离,小亚基和部分翻译起始因子继续保留在mRNA上。
①当氨基酸含量充足时,激酶GCN2 不响应,eIF2 未被磷酸化,eIF2B 鸟苷酸交换因子活性正常,将 eIF2 由 GDP 结合态转变为 GTP 结合态,后者状态的 eIF2 正常结合氨酰-tRNA 并转运至核糖体 P 位点;由于核糖体度过 ORF1 后可继续结合并在 mRNA 上移位。由于 eIF2·GTP·tRNA 三元复合物较充足,核糖体容易在 uORF 区域结合 tRNA 进而对 ORF2~4 中的任意一个进行翻译产生不具有生物学意义的短肽,而翻译后的核糖体从 mRNA 上脱离,不接触 dORF,GCN4 不表达;
②当氨基酸含量不足时,激酶GCN2 应激进而具有激酶活性,磷酸化 eIF2,磷酸化的 eIF2 无法被 eIF2B 交 换磷酸鸟苷,仍然处于 GDP 结合态,GTP 结合态的 eIF2 减少,则 eIF2·GTP·tRNA 三元复合物数量减少; 此时在 mRNA 上移位的核糖体小亚基不易遇到合适的 tRNA 并开始翻译,有更大机会度过 uORF 区域进入 大间隔区;由于大间隔区长度大,赋予了核糖体小亚基更多的时间让其有更大机会遇到合适的 tRNA 并在 dORF 区域开始翻译,GCN4 进而表达。
连续性
(Commaless)
编码蛋白质氨基酸序列的各个三联体密码连续阅读,密码间既无间断也无交叉。
简并性
(degeneracy)
遗传密码中,除色氨酸、硒代半胱氨酸和甲硫氨酸仅有一个密码子外,其余氨基酸有2、3、4个或多至6个三联体为其编码。
通用性
(universal)
蛋白质生物合成的整套密码,从原核生物到人类都通用。
密码的通用性进一步证明各种生物进化自同一祖先。
摆动性
(wobble)
转运氨基酸的tRNA的反密码需要通过碱基互补与mRNA上的遗传密码反向配对结合,但反密码与密码间不严格遵守常见的碱基配对规律,称为摆动配对。
方向性
(dirECTion)
起始密码总位于编码区5′末端,而终止密码位于3′末端,每个密码的三个核苷酸也是5′至3′方向阅读,不能倒读。